

There is a concern amongst some of the AI community that advanced systems will have a capacity to self-improve, leading to an uncontrollable intelligence explosion where systems continually bootstrap their capabilities—resulting in systems vastly more capable than humans that can exploit humans leading to potentially existential risks. These concerns are often founded on thought experiments and extrapolation arguments. The arguments leading to these more extreme scenarios of self-improvement involve the systems improving themselves through algorithmic advancements or increasing access to computing resources. Consequently, they require the system to develop instrumental goals. Moreover, they need the system to possess agentic capabilities, such that they can execute actions to instantiate these improvements. Furthermore, they assume scaling laws relating capabilities to resources continue to hold. There is much speculation as to whether these assumptions hold, and thus there is much dispute as to whether this extreme self-improvement scenario could be realised.
However, there is a mild form of self-improvement for which there is already evidence of a system almost performing. This form of self-improvement involves the system generating its data, on which it continues to train itself to improve its capabilities. The intuition here is that a sufficiently capable system can generate higher quality data than that it was trained on. Although this seems as though we are having our cake and eating it, this dynamic is reminiscent of a student-teacher dynamic. In this scenario, the student is the AI system and the teacher is a human expert. The teacher trains the students using their expertise, and eventually, the student can conduct their explorations and progress on the knowledge provided by the teacher. Throughout history, this dynamic has progressively expanded the scope of human knowledge and expertise, and thus it is plausible that an AI could bootstrap its capabilities through data generation.
Indeed, AlphaGo was initially trained using human examples of good moves in the game of Go. It was then left to play against itself and learn how to improve its capabilities. Eventually, it beat the leading human Go player. An attribute of the success of the resulting system was that its style of play was divergent from the well-established strategies found by human players. For instance, in one of the games the system played a move that contradicted common notions. The move would become known as move 37, as it turned out to be decisive for the outcome. Subsequently, AlphaGo has rejuvenated the scope of approaches taken to play the game of Go.
However, the AlphaGo system still had some flaws. A group of researchers discovered some adversarial examples for which the AlphaGo system failed, and hence they beat the system. This is perhaps to be expected, for the data generation process is likely to make the capabilities of the system rather brittle, for it only reinforces behaviour along a certain direction, and the blind spots of the system remain.
Simple Models
We can test this data generation form of self-improvement with a simple model. We consider a generative model trained to encode and decode images from the MNIST dataset, which is just a collection of hand-written digits.
We supply the model with an initial set of data, let it train on this data, generate a new set of data using the trained model, let the model continue training itself with this new dataset and repeat.
To relate this to the scenario of the intelligence explosion, we slightly corrupt the initial batch of data to reflect that human data may not be the ground truth. However, we evaluate the modelling during training using the ground truth, to simulate the higher intelligence level the model is striving for.
In our experiments, we consider an autoencoder model and a variational autoencoder. The corruption of the initial dataset comes in the form of random noise of varying amplitudes or horizontal lines of varying lengths added to the edges of the digits. For each model, we conduct a control experiment where no noise is added to the initial images.
In each experiment, the model is trained on 20 batches of data, 19 of which are self-generated.
For the autoencoder, our control experiment shows that the autoencoder continues to improve as it trains on its generated data. However, for the variational autoencoder, the loss immediately increases when it starts to train on its generated data. It is only after a few iterations that its loss decreases again, however, in our experiments the loss never arrives back at its original value. This perhaps reflects that the latent space of a variational autoencoder is regularised to resemble a probability distribution, therefore, as the images it generates lie on a different manifold to the original dataset the previously learned latent space is no longer applicable. Consequently, loss rises, and it takes the model many training runs to alter its latent space distribution to represent the new manifold on which its training data lies.

As we increase the amplitude of random noise corruption we see that this effect for the variational autoencoder still holds. Similarly, we see this effect when adding lines to the digits. However, in any case, we see that the model can recover and continue to improve towards the ground truth.
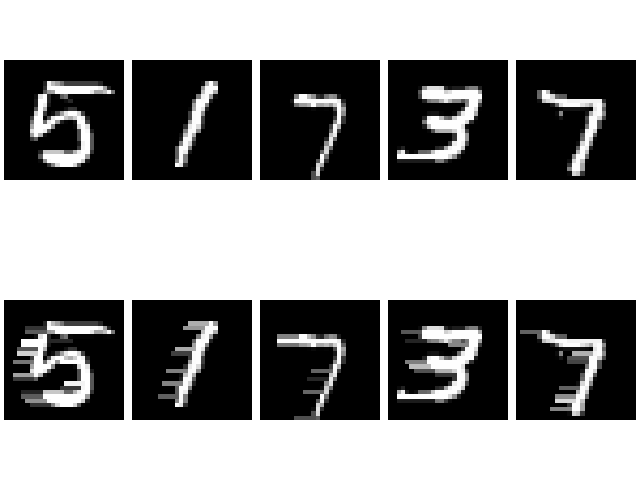

With the autoencoder, we do not see this initial loss in performance as the model continues to train itself on its own generated data. Instead, it continues to improve towards the ground truth. This is perhaps explained by the fact that the autoencoder has no regularisation on its latent space, and thus it is easier to adapt its latent representation to new inputs.
